
Arguably the most effective method to solve GraphQL latency issues is to simply cache the data.
The only problem is that GraphQL utilizes POST requests, which aren’t cacheable by default.
Therefore, most engineers must build their own GraphQL caching solutions, which is time consuming and requires very specialized knowledge.
As a result, building a proprietary caching solution is very costly, and even so, the end result typically lacks many functionalities that developers will need for maintenance, such as automated cache purging and observability metrics that show when and where latency issues occur.
What is GraphQL Latency?
GraphQL latency is the time it takes a GraphQL document to retrieve the requested data and show it to the user.
For example, if you’re browsing an ecommerce store and click on a product, the time between when you click on the product and when the page is displayed to the user is the latency.
Reducing latency is critical because users often leave if a page takes too long to load. Data also shows that slow loading websites are not only a nuisance, but also negatively impact a company’s bottom line, as a one-second delay makes page views drop by 11% and conversion rates drop by 7%.
Latency also negatively affects a website’s SEO performance, as page speed is an important ranking factor.
Challenges Associated With Solving GraphQL Latency
GraphQL latency issues typically arise for websites that have a high volume of data and users.
For example, the product page on an ecommerce website is more likely to have latency issues because it has many marketing assets, like videos, pictures, descriptions, and alternative product recommendations.
It’s also particularly problematic if the website receives a sudden traffic spike, like during Black Friday.
One of the best methods to solve latency issues is to implement a caching solution, as it speeds up the website’s load time by storing the data in the browser and reducing the trips the API must make to the server.
Caching also reduces the strain on your servers, which also reduces cloud costs.
While caching is fairly straightforward if you have a REST API, GraphQL uses POST requests, which aren’t cacheable by default.
Developers can build their own infrastructure to cache GraphQL requests, but this requires highly specialized engineering knowledge and many hours of labor, making it a costly endeavor for companies.
In addition, these caching infrastructures built in-house typically have a lot of blind spots.
For example, Datadog and Apollo Studio can tell you about errors and the time they take to resolve, but you won’t have granular insights into what data is actually cacheable and may waste time trying to further optimize semi-dynamic data that is already fully optimized. In addition you won’t have access to data like cache hit rates to discover where cache leaks are occurring to proactively solve them.
Therefore, building your own infrastructure to cache GraphQL data isn’t a perfect solution, but caching data is certainly one of the highest leverage opportunities to reduce GraphQL latency.
Below, we’ll discuss how you can easily solve latency issues with a slightly different approach to GraphQL caching.
How to Efficiently Improve GraphQL Latency
Tip #1: Cache Data With a GraphQL CDN That Leverages Edge Caching
We wanted a more cost effective and efficient solution to solve GraphQL latency issues with caching, though there wasn’t a GraphQL CDN available.
So we decided to build a solution!
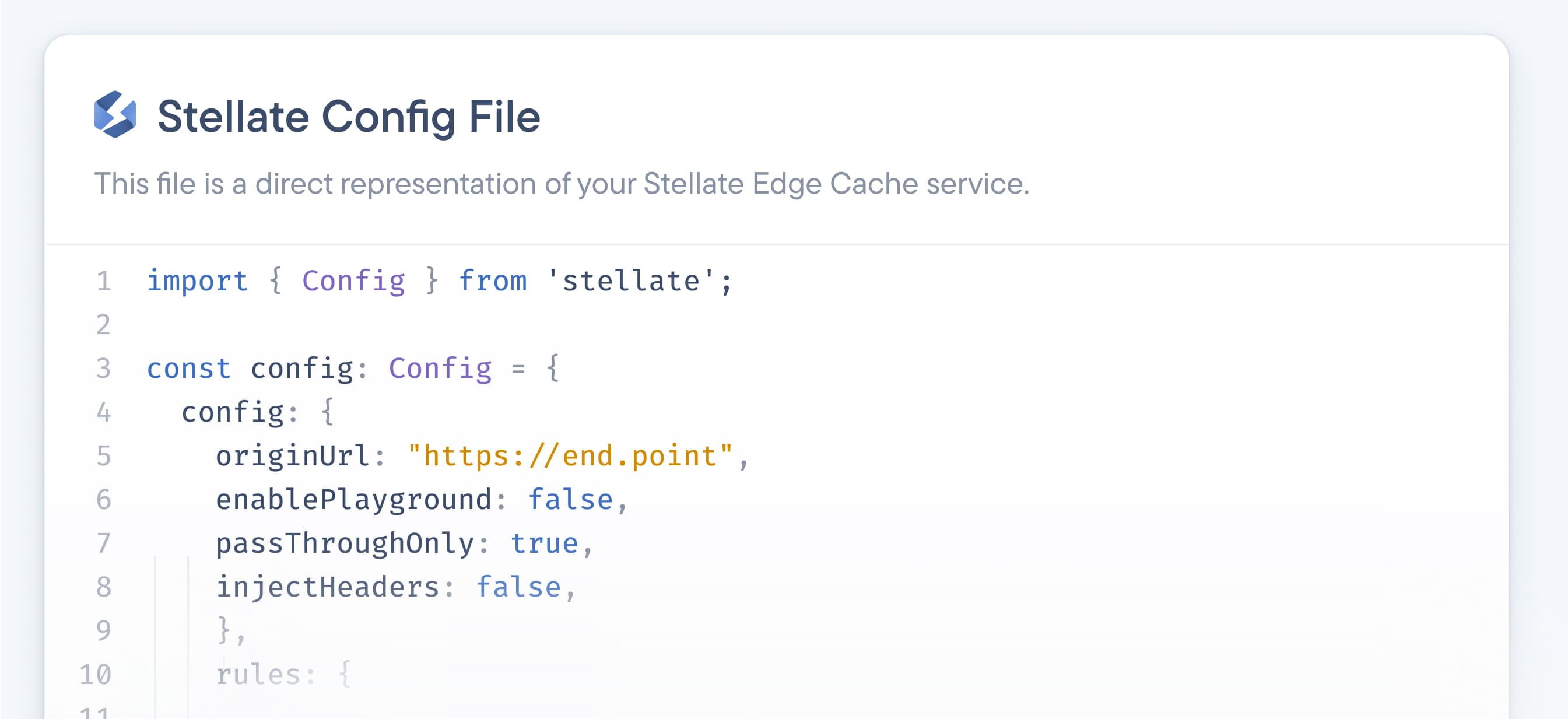
Today, Stellate is the first GraphQL CDN that allows you to automatically (or manually) cache data. It sits in front of your existing infrastructure (it works with any GraphQL API) and reduces your backend load.
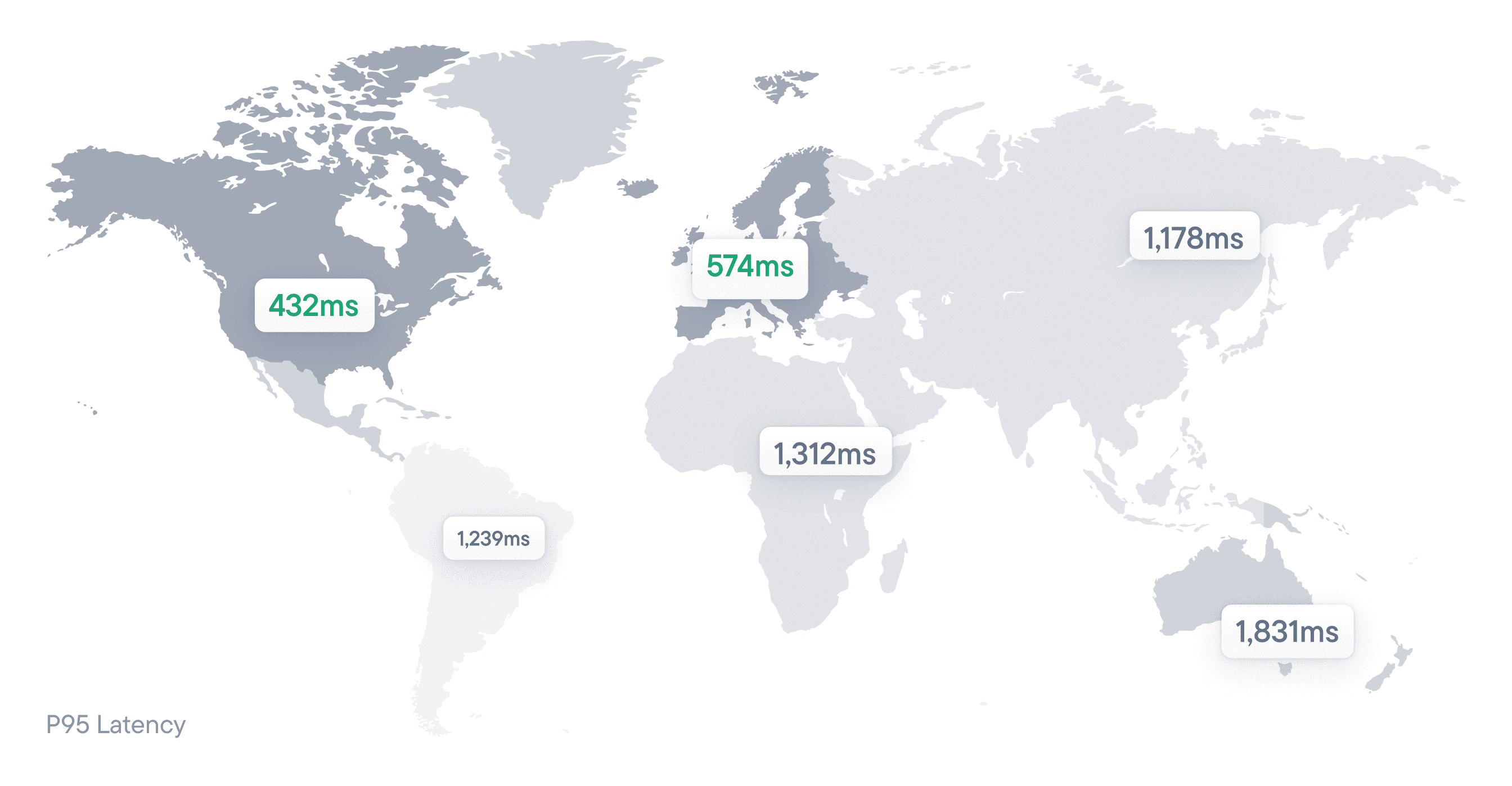
Caching the data and reducing the backend load prevents GraphQL latency issues, and our average response time worldwide is about 40 milliseconds. We also leverage edge caching, meaning users always receive data from the server closest to their geographical location, which further improves speed.
Our current server network consists of 98 different locations worldwide, so it’s well designed to serve a global audience.
In addition to resolving latency issues, using Stellate to cache your data also shields the API from massive traffic spikes that could cause the servers to go down.
For example, if you have a massive traffic influx on Black Friday, or you’re reporting breaking news, Stellate will cache the data the first time it is queried so that the server is only hit once.
This way, you never have to worry about the website going down during a peak event.
Tip #2: Prioritize Latency Issues Based On Revenue Impact
Another challenge with GraphQL latency is that it can be difficult to prioritize issues based on revenue impact because engineers typically lack observability metrics.
Datadog and Apollo Studio may give you basic observability metrics, but you won’t see where those latency issues occur on your website or which geographic regions they impact.
This makes it difficult to prioritize latency issues by revenue impact.
For example, you’d definitely want to solve a latency issue on the cart checkout page of an ecommerce site as that is likely directly causing revenue loss. In contrast, solving a latency issue on the about us page might not be as important.
Similarly, if you know you have a lot of high value customers in Canada, but very few in Japan, you’d want to prioritize solving the issues negatively impacting Canadians first as that will have a bigger impact on revenue.
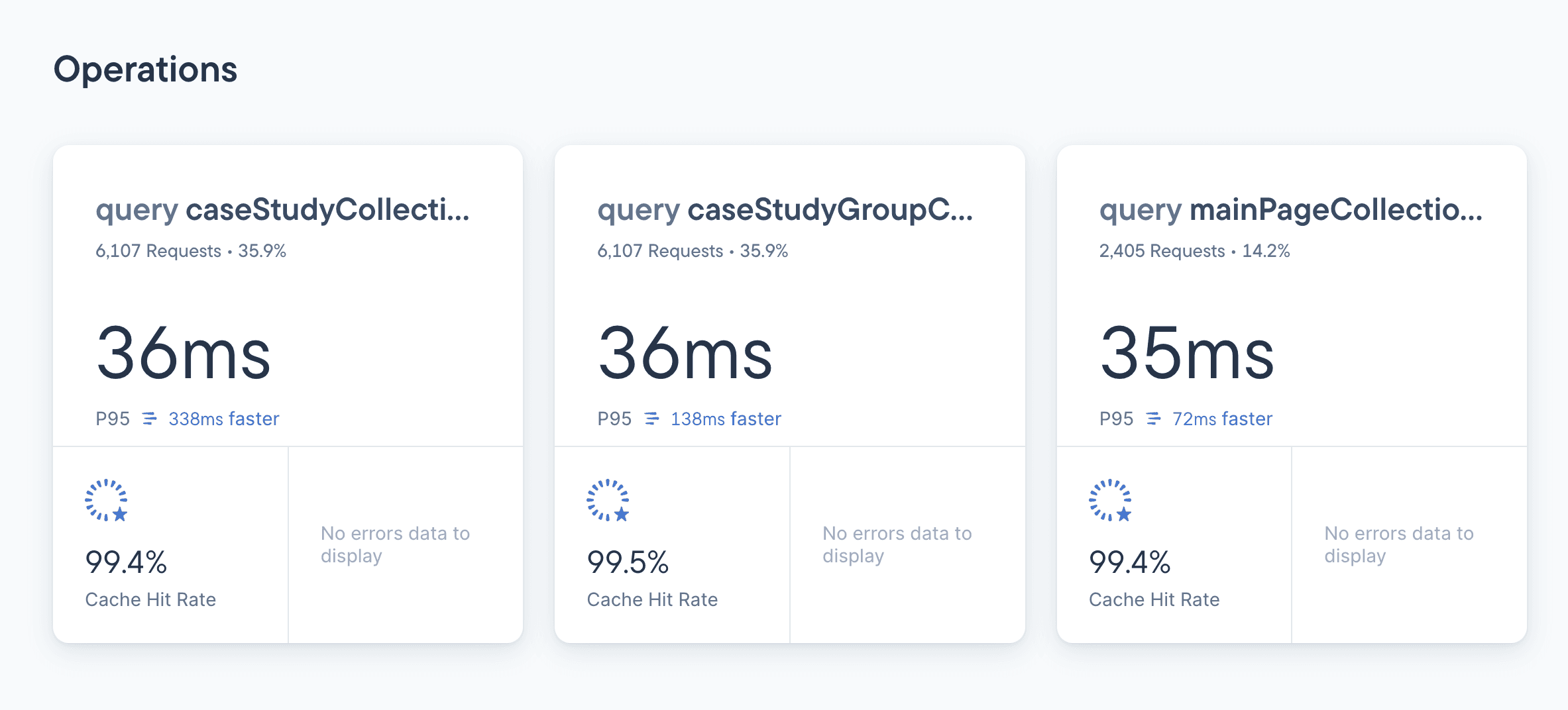
Stellate solves this by providing detailed metrics on not only latency, but also granular details on where the issue is occurring and who it is negatively impacting. This makes it easy for engineers to quickly identify the issue, assess its impact on revenue, and solve it.
In addition to providing these metrics, Stellate also offers alerts so that you can proactively solve high-impact issues before they negatively impact your users.
Tip #3: Proactively Prevent Latency Issues By Leveraging Alerts
For example, if the checkout page takes more than three seconds to load, it’s probably hurting conversion rates, so you can set an alert to be notified if that metric rises above a certain threshold. This way, you don’t have to wait for a customer to complain or constantly check the metrics dashboard to identify when high impact latency issues occur.

Tip #4: Incorporate Automatic Cache Purging
One of the biggest challenges with manually built GraphQL caching solutions is that there isn’t a method to automatically purge only dated information.
Instead, the only option developers have is to purge all of the data at once.
This negatively impacts performance because when the cache hit rate drops to zero, the server load skyrockets which will increase latency issues and could cause the servers (and ultimately the website) to go down altogether.
To solve these problems, Stellate allows you to automatically purge only selective data in about 150 milliseconds globally. For example, you can set it to purge the post with ID 10 and the cached query results containing it.
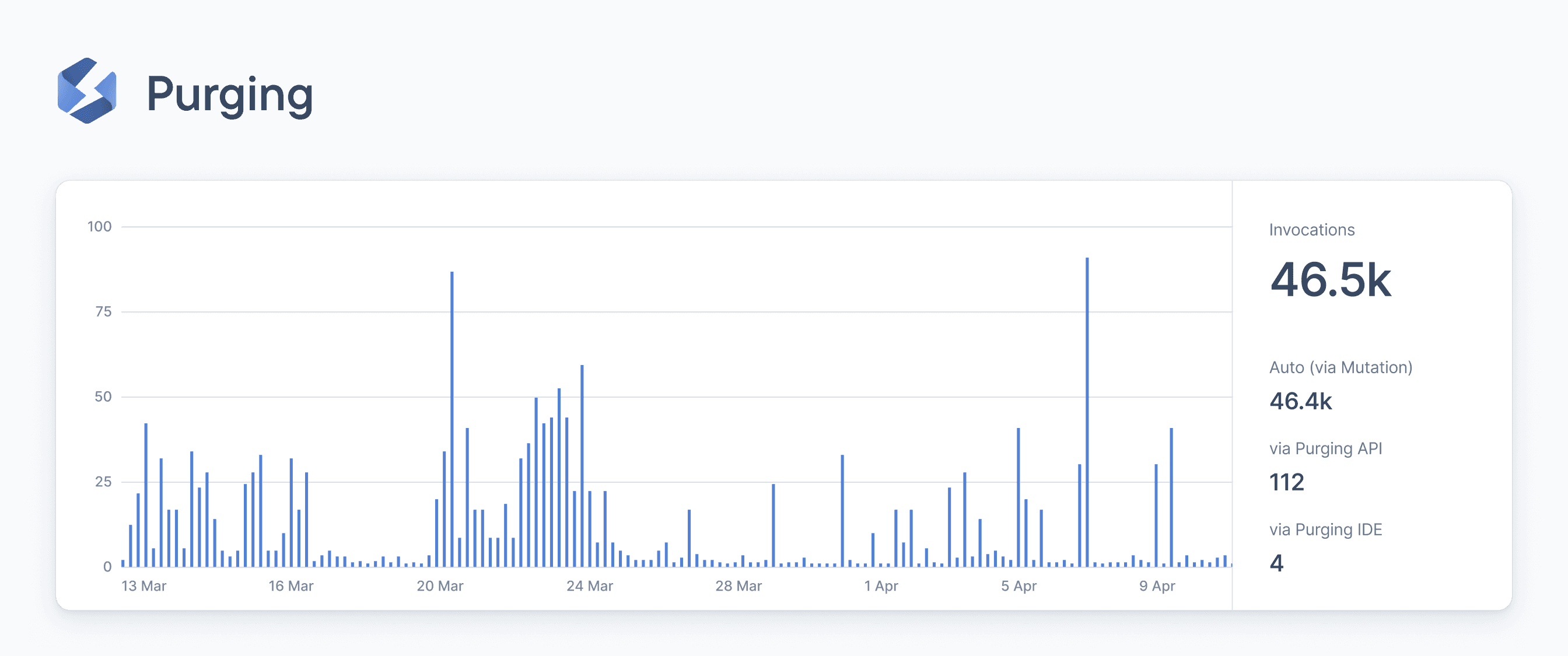
By selectively purging only dated information, the servers never become overloaded and your customers always see up-to-date information.
Selectively purging dated information also reduces cloud costs because the server isn’t hit nearly as many times.
If there are cases where you want to purge only a very specific set of data, you can do so by manually purging the data by a query, field, or name of operation.
Solving GraphQL Latency Issues: Case Studies
GraphQL latency issues are most common in websites with traffic spikes, like ecommerce websites and media websites, so below, we’ll discuss two different case studies that demonstrate how they solved GraphQL latency challenges.

Example #1: Reducing Latency For a Media Website By 40%
Australia’s leading automotive publication, Drive, has over three million monthly site visitors with news, commentary, and consumer resources covering all brands and areas of Australia's motoring industry.
Like many other media publications, they publish thousands of articles annually, but the problem wasn’t just the sheer volume of traffic that the website received. The biggest challenge was handling the traffic spikes.
For example, they occasionally publish highly in-depth articles, called Mega Test articles, which receive a massive influx of traffic when they’re first published. Unfortunately, these massive articles contain a lot of content and imagery, and rendering them fully uncached is detrimental to the website’s performance.
They needed a scalable solution that would make the website’s performance more reliable.
The best approach to solving the website’s performance problem was to cache the articles, as it would eliminate the need to render the articles uncached. The only problem was that they didn’t want to have to build their own caching infrastructure.
Instead, they decided to implement Stellate, the only GraphQL CDN that currently exists.
When Stellate was placed in front of their WPGraphQL APIs, it reduced API requests to WordPress by 85.6% which resulted in a 94.5% faster API response time.
As a result, Drive eliminated most of its latency issues, which resulted in a better user experience and also made it possible to further scale operations.
They also implemented automated cache purges, which allowed them to purge only outdated information, rather than purging all of the data at once, which further reduced website latency and server load.
In addition to improving website performance, implementing a caching system also allowed them to reduce infrastructure costs by 40% thanks to the reduction in API traffic.
Example #2: Reducing Latency For an Ecommerce Website
Black Friday traffic spikes are a high stakes challenge for ecommerce websites. Even if the website goes down for a few minutes, it could cost larger ecommerce stores thousands of dollars.
Italic, a luxury ecommerce website that experienced rapid growth over the past several years, experienced a massive traffic spike on Black Friday in 2020 that caused the website to crash every few hours.
To prepare for 2021, they decided to approach the server load issue by caching data.
To do so, they decided to just implement a GraphQL CDN, Stellate, to automatically cache data.
Prior to implementing GraphQL caching, the average cache hit rate was 86% while some of the top queries had a cache hit rate of over 99%.
After implementing Stellate, they had an 80% faster p50 API response time and managed to reduce server load during traffic spikes by 61%.

As a result, they significantly reduced latency issues and the average page load times were reduced by over a full second.
This helped them not only increase conversions, but it also helped them deliver an outstanding user experience on Black Friday.
Reduce GraphQL Latency Today
Caching data is the 80/20 of significantly reducing GraphQL latency, but building and maintaining a proprietary caching infrastructure simply isn’t an option for many companies due to the high engineering costs and specialized knowledge required to do so.
Even if you do build a GraphQL caching solution, you’ll likely find that it’s not easy to maintain and proactively solve GraphQL challenges.
That’s why we built Stellate, the first GraphQL CDN that allows any GraphQL users to reap the benefits of edge caching without building your own solution.
It also gives you all the observability metrics you need to further optimize performance, prioritize issues by revenue impact, and proactively solve them before they impact users.
To see for yourself how Stellate can help you solve GraphQL latency challenges, sign up for free today.