@defer Support
Stellate now offers support for an experimental use of the GraphQL @defer directive with Partial Query Caching (PQC). When you enable our supported experimental @defer directive in your config file, Stellate’s partial query cache becomes aware of the directive. This makes it possible to:
- Improve query latency, sometimes enabling the return of cached data to the client even before an origin request is made.
- Make a notable, positive impact on the user experience you can provide.
What is GraphQL Defer?
The GraphQL Defer (@defer) directive is a proposed addition to the GraphQL standard. This standard allows clients to deprioritize the marked data of a query, which is then streamed back after critical data has been send first.
For detailed information about the proposed @defer directive, see the
following resources: - The original RFC: GraphQL Defer and Stream
Directives .
- RFC edits to the original RFC, which are widely accepted and implemented among defer-stream-supporting servers. - Latest in-progress proposal .
Why Use @defer with PQC?
At Stellate, we evolved our document cache (i.e. caching the entirety of a GraphQL response) into a partial query cache. Partially caching GraphQL response data means:
- We effectively split up response data into multiple cache buckets based on different requirements such as differing max-ages and scopes (Scopes).
- We make it possible for you to achieve higher cache hit rates than previously possible for many use cases.
- You can greatly reduce traffic to your origins, saving costs in reduced compute time and bandwidth requirements.
With PQC, however, the end-user will not necessarily notice latency improvements, since we still need to serve a full GraphQL response, even if some parts have been retrieved from cache. This is where use of the @defer directive comes into play.
Use case: speed up UI rendering with @defer
One of the many notable scenarios where you can benefit from using the @defer directive with PQC, is to use @defer to speed up the initial rendering time for complex UIs, without splitting up your GraphQL query into multiple queries. The client can render the most important parts of the web page from the initial payload, while waiting for large-sized or computationally expensive data to arrive before rendering the complete UI.
Enable Experimental @defer Support
Enabling our experimental @defer directive support takes a few simple steps.
- To use the
@deferdirective, check that both the used client and origin server support@defer.
@defer/@stream RFC is constantly evolving. Stellate implements @defer support based on the RFC edits , but due to the nature of the RFC, future versions of servers and clients used may become temporarily incompatible until the standard stabilizes.
-
Open your Stellate > Service > Config file to enable experimental defer support and set
partialQueryCaching.enabledtotrue. -
Then set
experimentalDeferSupporttotrueas shown int the following Stellate configuration file snippet:
partialQueryCaching { enabled: true, experimentalDeferSupport: true }Remember, you must set partialQueryCaching.enabled to true, otherwise experimentalDeferSupport: true has no effect.
Considerations When Using @defer
Stellate’s @defer support is an experimental feature. As such, when trying it out be aware that:
- Bugs can happen.
- Breaking changes can happen.
We encourage you to try it and report back to us. We’re grateful for any reports on errors, bugs, or positive experiences you have with this feature.
PQC Defer Functionality
In this first version of @defer support, Stellate will never cache anything marked as deferred. We specifically optimized the first version for the common use-case where certain data is excluded from caching, which requires it to be fetched fresh from the origin on every request.
eCommerce shop example
To illustrate PQC Defer functionality, in the following example, if we have an e-commerce shop we might have a Stellate config stating that products should be cached except for their price and availability:
// Stellate config excerpt.
partialQueryCaching: {
enabled: true,
experimentalDeferSupport: true
},
rules: [
{
types: ['Product'],
maxAge: 900,
description: 'Cache products for 15 mins',
}
],
nonCacheable: [
'Product.availability',
'Product.price'
]eCommerce query without @defer
First, let’s look at the query without using @defer. When fetching a list of products from our e-commerce store, we make the following query:
query Products {
products(limit: 50) {
id
name
description
availability
price
}
}Assume the uncached query takes one second. Based on the configuration, id, name and description can be cached and returned in about 50ms from an edge location. However, the full response requires waiting for the origin to return availability and price. This means that the time-to-first-byte latency will always include the roundtrip from Stellate to your origin. If served partially from cache, we can save bandwidth. It’s safe to assume, however, that most of the one second it takes to resolve the query is network and data store access, meaning that there will likely be a negligible difference in end-user latency between the partially cached and uncached query.
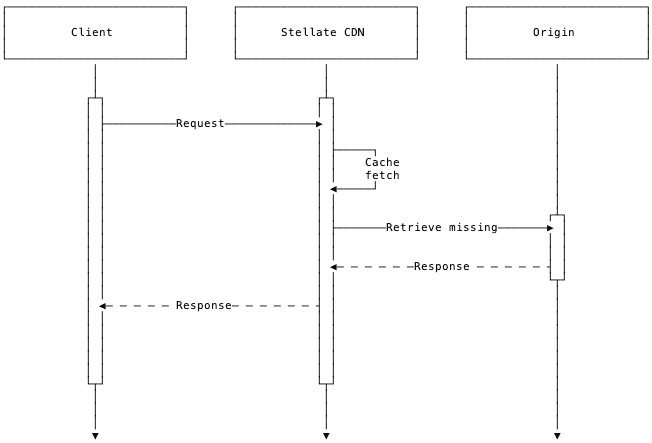
eCommerce query with @defer
With defer, the same query can be expressed as follows (using the same configuration):
query Products {
products(limit: 50) {
id
name
description
... @defer {
availability
price
}
}
}The defer directive will change the typical request-response pattern that GraphQL over HTTP uses into a request-response stream, divided into initial and incremental chunks:
// Initial
{
"data": {
"products": [
{
"id": 1,
"name": "Fancy shoes",
"description": "..."
},
{ /* ... */ }
]
},
"hasNext": true
}
// Incremental
{
"incremental": [
{ "data": { "price": "49.99", "availability": 15 }, "path": ["products", 0] },
{ "data": { "price": "19.99", "availability": 11 }, "path": ["products", 1] }
],
"hasNext": false
}The initial chunk is similar to a regular GraphQL response, except the indicator that there’s more to follow (via next: true). Under the hood, the stream is either text/event-stream or multipart/mixed, depending on the negotiated content type. Incremental chunks then add on top of the inital chunk, building up the full result over time.
Latency Benefits with Defer
So what about the latency benefits compared to the non-defer version of the query? It’s important to understand that the amount of latency benefits you can get when using @defer and Stellate are, at the moment, directly linked to how cacheable the non-@defer parts of the query are. If there are non-cacheable pieces contained in the non-deferred part of the query, then Stellate will always have to reach out to the origin to retrieve those parts in order to send back a complete initial response.
We will not immediately send back any subset of the initial payload we can retrieve from cache while waiting for the rest. Example: Assuming we have id and name in the cache, but not description, we’d not send those two fields back, but we wait for the origin to at least return description before doing so. Sending an incomplete initial payload back immediately would result in an invalid response, meaning that the client expectations about the response shape would not align with the actual response.
With that in mind, we assume that the initial payload is completely cacheable for the following two scenarios.
Scenario 1 - No or incomplete cache for the initial payload
If there’s no or incomplete data for the initial payload, Stellate needs to wait for an origin response to return any data. Since the origin will still return the non-deferred parts early, there’s a latency benefit compared to the non-defer query, but the origin roundtrip time will not be eliminated, meaning you’d still be fairly close to the original one-second latency, depending on how fast the initial payload can be resolved by your server:
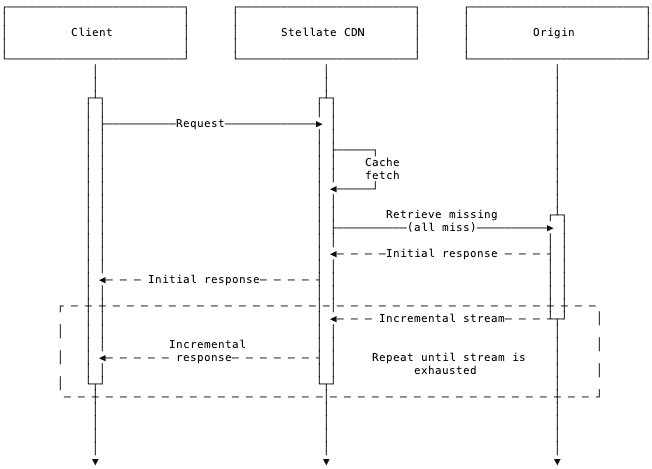
Scenario 2 - All data from the incremental payload can be retrieved from cache
In the second case, all data for the initial response can be retrieved from cache, so Stellate will construct the initial response and return immediately, requiring no roundtrip to the origin, which eliminates a large part of the one-secnd first-byte latency we had previously. Since Stellate’s caches operate on a large edge-network, a sub-100ms, or even sub-50ms, response time for clients close to edge locations is possible, which would mean latency is cut by >90% overall.
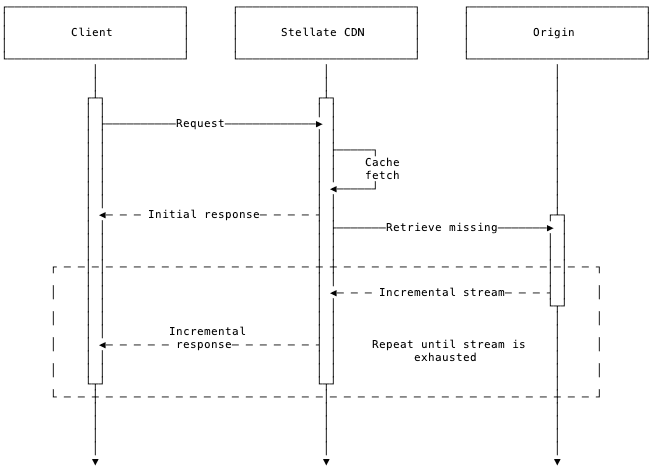
Limitations When Using Defer
This section summarizes already mentioned limitations and points out cases where we know the current experimental version to have shortcomings.
@defer parts are uncacheable
The entire sub-document starting from a deferred selection set or fragment is automatically uncacheable, even if rules apply to the contained types or fields.
Object and list inconsistency
Serving partial data from cache has a risk of not matching data returned from the origin. A common example is list inconsistency, where the order of elements contained in the cache does not match the order returned from the origin. Stellate is actively detecting these inconsistencies and will attempt to restore consistency in the cache. For non-defer requests, this is the only case where Stellate will send a second request to your origin to rebuild the cache. The following illustrates the issue without @defer:
# Full query
query {
blogPost(id: 1) {
comments {
id
content
author {
name
}
}
}
}
# Assume cache entry 1:
query {
blogPost(id: 1) {
comments {
id
content
}
}
}
# => { "data": { "blogPost": { "comments": [{"id": 1, content: "..."}, {"id": 2, content: "..."}]} }}
# Assume cache entry 2:
query {
blogPost(id: 1) {
comments {
id
content
}
}
}
# => { "data": { "blogPost": { "comments": [{"id": 2, "author": { name: "..." }}, {"id": 3, "author": { name: "..." }}]} }}The first cache entry contains comments 1, 2, the second 2, 1. This will cause Stellate to reach out to the origin with a full request again to restore the cache as mentioned above.
Similar to the listing shown above, @defer can also encounter consistency issues. In particular, it introduces a case where Stellate is unable to restore consistency. Instead, it requires that you recact to consistency errors and retry the request. The process is as follows:
- When the entire initial payload is constructed from cache, we immediately return without reaching out to your origin.
- If the incremental responses from the origin then surfaces an inconsistency with the cached data, we’re unable to retract the initial payload as we’ve already sent it.
- While we will still return the incremental payloads from the origin, we will also render an error into the incremental payloads warning you of the detected inconsistency.
- In the background, the inconsistent caches will be purged, so a retry will warm the caches with consistent data again.
# Full query
query {
blogPost(id: 1) {
comments {
id
content
... @defer {
author {
name
}
}
}
}
}
# Non-deferred, cacheable parts.
query {
blogPost(id: 1) {
comments {
id
content
}
}
}
# => { "data": { "blogPost": { "comments": [{"id": 1, content: "..."}, {"id": 2, content: "..."}]} }}
# => All non-deferred parts are retrieved from cache, return data immediately.If the incremental response would then look like this:
{
"incremental": [
{
"data": { "id": 2, "author": { "name": "..." } },
"path": ["blogPost", "comments", 0]
},
{
"data": { "id": 3, "author": { "name": "..." } },
"path": ["blogPost", "comments", 1]
}
],
"hasNext": false
}Stellate would detect an inconsistency as the elements are different, add an error and return all data:
{
"incremental": [
{
"data": { "id": 2, "author": { "name": "..." } },
"errors": [
{
"message": "Found inconsistent data while processing the response stream, different partial results might refer to different entities.",
"extensions": {
"stellate": {
"code": "E1001"
}
}
}
],
"path": ["blogPost", "comments", 0]
},
{
"data": { "id": 3, "author": { "name": "..." } },
"path": ["blogPost", "comments", 1]
}
],
"hasNext": false
}Automatic @defer inlining by the origin
Origin servers can decide to ignore @defer in favor of returning a complete response instead of streaming increments. If we retrive the entire initial payload from cache, we return that data immediately before reaching out to your origin. Right now, we expect the server to send back increments, but if the server decides to return a regular GraphQL execution result instead, we will abort internal processing and just return the data. We’re working on improving this so we transform the origin response into increments transparently, but right now it will cause an error:
# Full query
query {
blogPost(id: 1) {
comments {
id
content
... @defer {
author {
name
}
}
}
}
}
# Non-deferred, cacheable parts.
query {
blogPost(id: 1) {
comments {
id
content
}
}
}
# => { "data": { "blogPost": { "comments": [{"id": 1, content: "..."}, {"id": 2, content: "..."}]} }}
# => All non-deferred parts are retrieved from cache, return data immediately.
# Origin query:
query {
blogPost(id: 1) {
comments {
id
... @defer {
author {
name
}
}
}
}
}Origin returns:
{
"data": {
"blogPost": {
"comments": [
{ "id": 1, "author": { "name": "..." } },
{ "id": 2, "author": { "name": "..." } }
]
}
}
}This would cause us to send back:
{
"data": {
"blogPost": {
"comments": [
{ "id": 1, "author": { "name": "..." } },
{ "id": 2, "author": { "name": "..." } }
]
}
},
"errors": [
{
"message": "Unhandled @defer case: Origin inlined defer, but initial payload was already constructed from cache.",
"extensions": {
"stellate": {
"code": "E1001"
}
}
}
]
}Stellate Streaming Errors
Streaming errors are inserted wherever errors can be set in GraphQL responses:
// Regular execution results.
{
"data": { /* ... */ },
"errors": [
{
"message": "<message>",
"extensions": {
"stellate": {
"code": "<error code>"
}
}
}
]
}
// Incremental execution results.
{
"incremental": [
{
"data": { /* ... */ },
"errors": [
{
"message": "<message>",
"extensions": {
"stellate": {
"code": "<error code>"
}
}
}
],
"path": [/* ... */]
}
],
"hasNext": false
}@defer Error Codes
Possible @defer error codes are:
- E1000: Origin server inlined
@deferin the response after cache data has been sent back already. - E1001: Inconsistent data detected after cache data has been sent back already. To get consistent data, you need to retry the request.