Major product drops or events like Black Friday and Cyber Monday are tricky to prepare for as you’re dealing with a traffic spike rather than a general traffic increase. This means you won’t really know if your systems can handle the additional traffic until the day of the event.
However, if you implement the right scalable systems, your website will be better equipped to meet the additional traffic you’ll undoubtedly receive during big sales events.
In this post, we’ll discuss these systems and provide actionable optimization tips to prevent your website from crashing during big sales.
Tip #1: Use a CDN
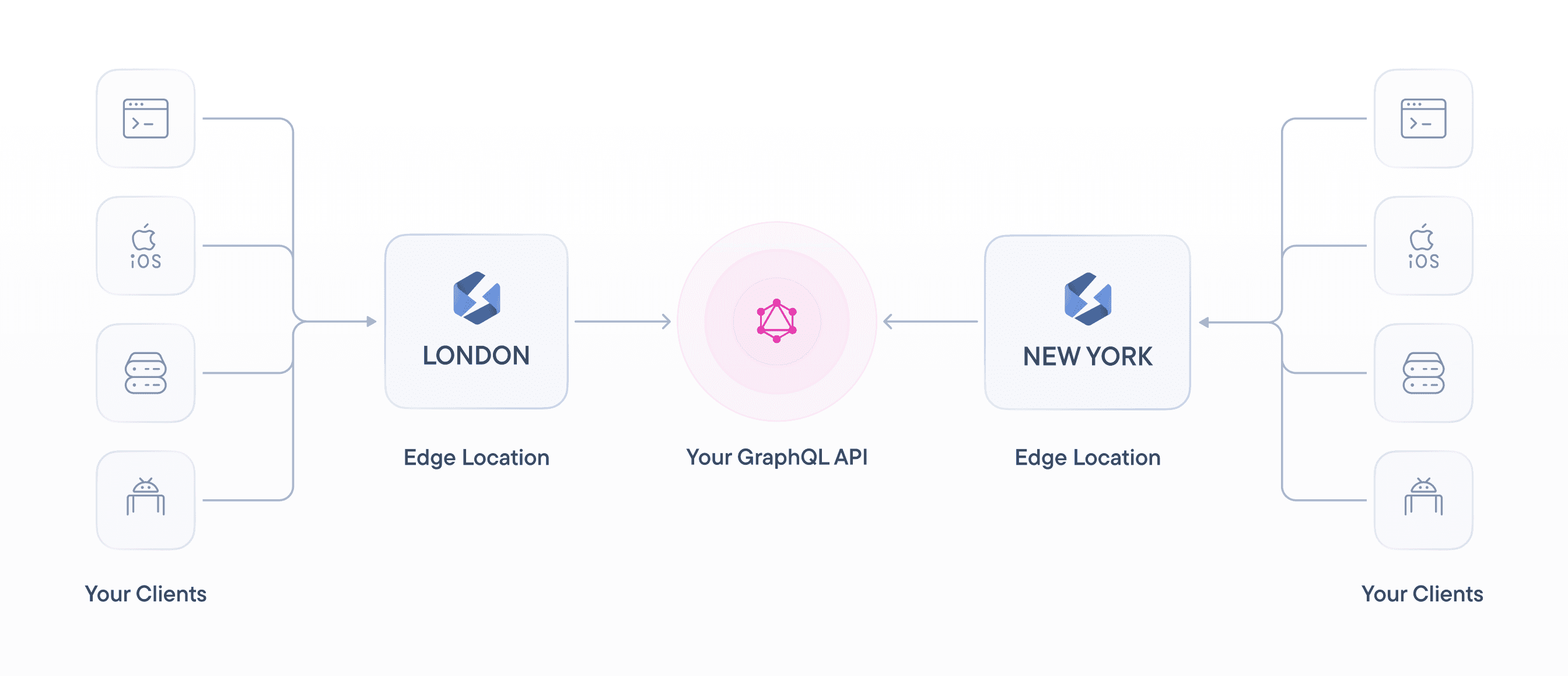
Using a CDN reduces the probability of your service going down. Even if there's an issue with one edge location, the traffic can be automatically re-routed to any of the other edge locations in the network. That means your website will continue functioning without interruption for end users.
A CDN can also speed up your website because:
The user receives the data from the server that's geographically closest to them.
The server load is distributed across a network of servers rather than a single server.
All of these factors make CDNs improve the scalability of your website so that it can handle massive traffic spikes efficiently and maintain excellent performance.
If you're using a REST API, there are plenty of CDNs, like Cloudflare, Fastly, and Akamai, but GraphQL users don't have the same luxury as these CDNs are natively designed to handle GraphQL queries.
As a result, most GraphQL users are forced to build their own solutions, which pulls the engineering team away from improving the core business.
To solve this problem, we built Stellate, the first GraphQL CDN that offers edge caching.
The product sits in front of your existing infrastructure and is able to cache GraphQL requests.
It supports all GraphQL APIs and offers various features to optimize your caching strategy, like automatic and manual purging and observability metrics.
By implementing edge caching with Stellate, you can significantly reduce API traffic, which reduces cloud costs and improves performance.
As a result, your website will be set up to efficiently handle traffic spikes during big sales and your engineering team can focus on higher value activities that contribute to business growth.
Tip #2: Use a Scalable Cloud Hosting Solution
If you don't have a scalable cloud hosting solution, your website will simply crash if the traffic spike exceeds your cloud hosting solution’s resources.
Using a scalable cloud hosting solution solves this problem as it will scale to meet user demand, and you'll simply be charged by usage.
As you're evaluating different cloud hosting solutions, here are a few things to consider:
Vertical scalability: This makes the existing servers bigger by adding more power, such as CPU, RAM, disk space, or network bandwidth, to a single server.
Horizontal scalability: This adds more servers rather than increasing the power of a single server. Horizontal scaling is generally preferred as adding more resources to a single server becomes increasingly difficult and expensive beyond a certain size, while adding more servers will always scale linearly.
Pricing: Rather than just checking the base price, check the pricing as you scale. Some solutions may be cheaper at a lower usage level, though as you scale, the cost could increase sharply.
Support for auto-scaling: Ensure the hosting solution takes care of adding more servers when there are traffic spikes so that you don't need to manually add and remove servers depending on the amount of traffic your website receives.
You'll also need to consider whether you'll want to rent servers or operate serverless.
Renting servers is the traditional hosting model, and it gives you the liberty to do what you want with the given server size you rent.
Though in recent years, more and more companies are choosing to operate serverless. This means you're not paying for a complete server but instead paying for individual function executions on any server which you don't own anymore.
The huge upside of this is that your costs are directly tied to the amount of traffic you receive, and you don't need to worry at all about scaling – the hosting company takes care of that for you by ensuring there are enough servers available at all times to run your functions.
The downside is that you have no guarantee that the function is always readily available. This can lead to slower performance if you run into a cold start (the function is not actively running when a request comes in, so it takes an extra second or two for the first requests until the function can be executed).
Once there's a period of no traffic, the hosting provider might choose to evict your function to make room for other things, and then the next request will again suffer a delay because of a cold start.
Tip #3: Cache Your Data
Caching your data is one of the most fundamental things you can do to improve website performance and prevent a crash during traffic spikes because it shows the user a copy of the data they request rather than forcing the API to travel back to the server to retrieve the data.
As a result, you'll reduce server load and improve site speed because it's much faster to show the user the copy of the data stored in the browser than waiting for the API to travel to the server to retrieve the data.
However, if you want to take your caching to the next level, implement edge caching. Edge caching leverages a network of servers across the globe.
This provides data redundancy, which protects your website from crashing in the event that one server goes down.
Edge caching also further improves load speed as you can send the user the data from the server within the network that's geographically closest to them.
The only problem is you cannot cache GraphQL APIs using the caching directives built into HTTP, which is how you would cache a REST APIs. Therefore, GraphQL users traditionally had to build their own edge caching systems because an out-of-the-box edge caching solution didn't exist.
Building your own caching system is a costly endeavor as it requires a lot of valuable hours from the engineering team, and even after it's built, the engineers still have to spend time maintaining it.
So we decided to build Stellate – the first GraphQL CDN specializing in edge caching.
Stellate leverages Fastly's 98 edge locations and provides all the features you need to optimize your caching strategy out of the box. Here are just a few of those features:
Fine-grained cache control: You can create custom rules to specify which GraphQL query results to cache for how long based on types and fields.
Automatic invalidation using mutations: If there are any changes to the product data, Stellate's automatic mutation invalidation will automatically invalidate that data so that customers always see up-to-date information.
Manual invalidation: You can use the Purging API provided by Stellate to purge any data from the cache and it will do so in less than 150 milliseconds globally. You can manually purge a single query, type, operation by its name, and more.

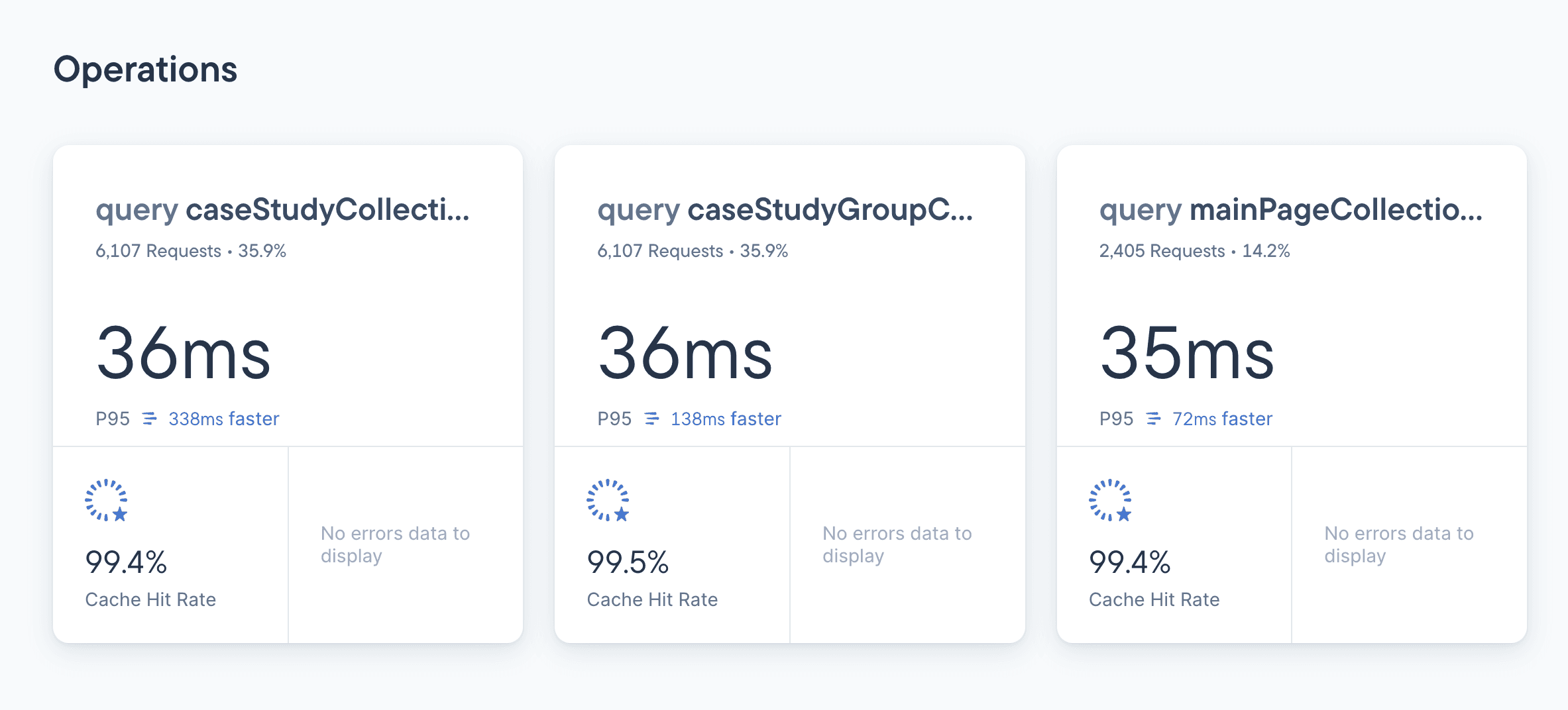
Stellate also provides observability metrics that make it easy to optimize your cache hit rate by showing specific metrics like cacheable bandwidth, requests, latency per second, and even a list of caching improvement opportunities ordered by impact.
For example, you can see here that the first priority should be optimizing the product listing page to improve the cache hit rate by 9.6%, and then the next priority should be improving the user profile as that can improve the cache hit rate by 7.8%.
This way, your team can quickly optimize your caching strategy and allocate most of their time to improving your core business.
Tip #4: Set Up Alerts For Errors And Performance
If an issue does arise on Black Friday, you want to know about it instantly to minimize its impact on sales.
To do this, set up alerts for critical steps in your sales funnel so that you know when an issue arises that directly impacts revenue. For example, you might want to add alerting for specific functionalities like add to cart, the login screen and the payment page.
If you're using Stellate, you can set alerts for errors and performance issues.
For errors, you can track HTTP errors within the 4xx and 5xx status code ranges, and also GraphQL errors (errors that happen during the execution of a GraphQL request).
To create an alert for an error, first select the error type you want to track. Then, you can set a threshold for when the alert should be triggered, based on the absolute number or percentage of times the error occurs. You can also set alerts based on how quickly the number or percentage of errors increase within a given time period.
To set up a performance alert, you can select between a P95 query duration (operations that fetch data) or P95 mutation duration (operations that fetch data that would alter some state on the server).

The alert creation process for performance issues is the same as it is for errors; you can either set it to alert you when the error reaches an absolute value (either a number or percentage), or set it to alert you when the issue increases by a certain value within a given timeframe.
The benefit of an error tracking solution like Stellate is that it not only tells you when issues arise, but it also gives you the data you need to quickly identify and diagnose the problem.
Specifically, here are just a few key data points that it will show you:
Where the error occurred in the GraphQL operation
The user’s geographic location
The device the issue occurred on
How many unique users it impacted
During major sales events, every second wasted trying to fix the problem results in lost sales, so having access to diagnostic data is critical.
Tip #5: Execute Stress Tests
To stress test, you choose a set of scenarios that impose high stress on your server. Typical scenarios include:
A high volume of requests
Requests with very big payloads
Requests that are very costly to execute
Many concurrent requests that access or mutate the same entity
You perform these scenarios against a testing environment which should mirror your production environment to see how well it copes with the stress. Often times it's necessary to use automated tools that perform these scenarios for you.
Here are a few additional tips to help you improve stress testing:
Tip #1: Don't execute stress tests against production.
You don't want to interrupt services to your customers. Either use an existing staging system, or spin up a dedicated testing environment that is as close to production as possible.
Tip #2: Use real data for stress testing.
Real customer data might be very different compared to what you might have in your staging environment. Replay real requests that you observed in production if possible.
Tip #3: Use existing tools.
It's more than likely you're not the first person doing stress testing. Use automations when possible, and look for common scenarios that others have tested.
Tip #6: Have A Strong Backup And Recovery Plan In Place
Preventing a website crash is ideal, but if a website crash does occur during a big sale, having a strong recovery plan in place to quickly get the website back online can minimize damage.
As you create your backup strategy, be sure to first write it out in a manner that's clear enough for anyone on your team – even your most junior engineers – to execute.
Then, actually practice recovering the data with the new plan.
If you don't practice beforehand, you may discover that you don't know how to recover the data or that the data is in the wrong format. Regardless, you want to be confident that you can execute the recovery plan in a timely manner before Black Friday.
Tip #7: Follow Basic Website Performance Best Practices
Plenty of websites crash during big sales simply because they didn’t abide by basic website best practices, like:
Optimizing your code
Compress images and implement lazy loading
Minimize plugin usage
Implementing security measures to prevent attacks
Even if your website performance is pretty good right now, any small issues caused by overlooking best practices will be magnified when you experience a traffic spike.

Take The First Step To Prepare Your Website For Big Sales Now
Most websites crash during big sales simply because one of the steps above was overlooked. Simply following this checklist should prepare the website to efficiently traffic spikes and ensure the sale runs smoothly.
However, GraphQL users typically find it difficult to execute many of the recommended steps within this post, like caching your data, simply because the engineering team traditionally had to build a system.
We believed there should be a solution that allows GraphQL users to enjoy the same simplicity as REST users, so we built Stellate, the first GraphQL CDN that offers edge caching and out-of-the box metrics and alerting.
To learn more about how Stellate can help GraphQL users manage traffic spikes and give your team peace of mind try it out for yourself today.