
Recently I learned about the phrase "If I Had More Time, I Would Have Written a Shorter Letter" and its contested origins. While authorship is unclear, its meaning is crisp: if done right, complexity often hides behind tidy and unspectacular surfaces. People just took enough time to do it well, so it seemed butter smooth and easy to you.
If you have been following our progress for a while, you may remember that we made cache misses 2x faster last year. This was a massive effort, but from a user perspective it ultimately leading to a simple toggle:

Fairly easy, right? You click the toggle and.. nothing happened? Good news, this is exactly how we envisioned our grand plan to play out. In the background, though, a lot happened. Let's dive in!
The Why
A quick recap on the situation is necessary to understand the context in which we are operating.
An existing system component handling users' traffic is established and running, providing a piece of the core functionality of Stellate.
A new system component is built to replace the old one, to integrate more tightly with our infrastructure ambitions and to allow for easier development of new, more complex features.
The two systems were written in very different ways but the intention was for them to behave identically. The same inputs should result in the same outputs. All responses Stellate return are targeted towards our users' user ("end-user") and any change in the response can potentially cause trouble. This is known as "backwards compatibility". It was critical for Stellate’s CDN to stay backwards compatible as we handle billions of requests per month for hundreds of services.
If you want to know why we set out to replace the old system, I have published a separate article about this here.
Flying in parallel
Changes to a system are not done overnight... I mean, the deployment may happen overnight. The development, on the other hand often takes weeks, if not months. So we followed industry best practices and allowed ourselves to have both systems running in parallel from the very get go.
This allowed us to opt-in specific Stellate services to the new system, routing their traffic through the new component. This allowed us to continuously deploy and test our new system in the real world against our own production services without any downsides to our users.
While we prepared existing users for the move we realized we couldn’t guarantee a 100% exact replication of the old service.
So we would eventually want no new services to make use of the old system component. We knew the same opt-in system could be used for new services. The question was just: when?
There was a chicken-egg problem: if we prematurely put users onto the new system, any change to the new system would break backwards compatibility for them. But changes to the new system are necessary to eliminate any inconsistency between the old and new system component.
"Hollup.. let's take a step back"
"Pon de Replay"
In my past job at Contentful, I had success with a replay system, which in theory was quite simple:
Once a request comes in, a request is randomly sampled.
If so, we just run the request normally (ie. a request to the old system component is made), the response is captured and used for the normal hot code path of the request
The remainder of the request is executed.
Once the response is completed, a request to the new system component is made and its response is compared to the captured one from point 2.
Any difference is logged for further inspection.
We decided to adapt this "traffic replay" pattern, but had to apply some more constraints to it:
Both systems would reach out to the user's origin. This is bad for multiple reasons and need to be avoided.
Increases in requests is not really what users are expecting using a
cache.
In between the two requests, data from the origin service may change, leading to false positives in change detection
Mutations have side-effects. Sending them twice can seriously put the integrity of our user's data at risk.
Responses that come back are our users' data, capturing them is risky. We need encryption, access control and a low retention time. No Stellate engineer ever looks at what goes through our pipes and we are proud we don’t have to. So we were extra careful here to only store what’s necessary for the least amount of time.
Not the full response is logged as a difference, only the "leaves" in the JSON that are different are logged.
With that in mind we set out and built the system. Here’s an internal flow diagram from the design phase that shows how capturing and replaying fits into the system:
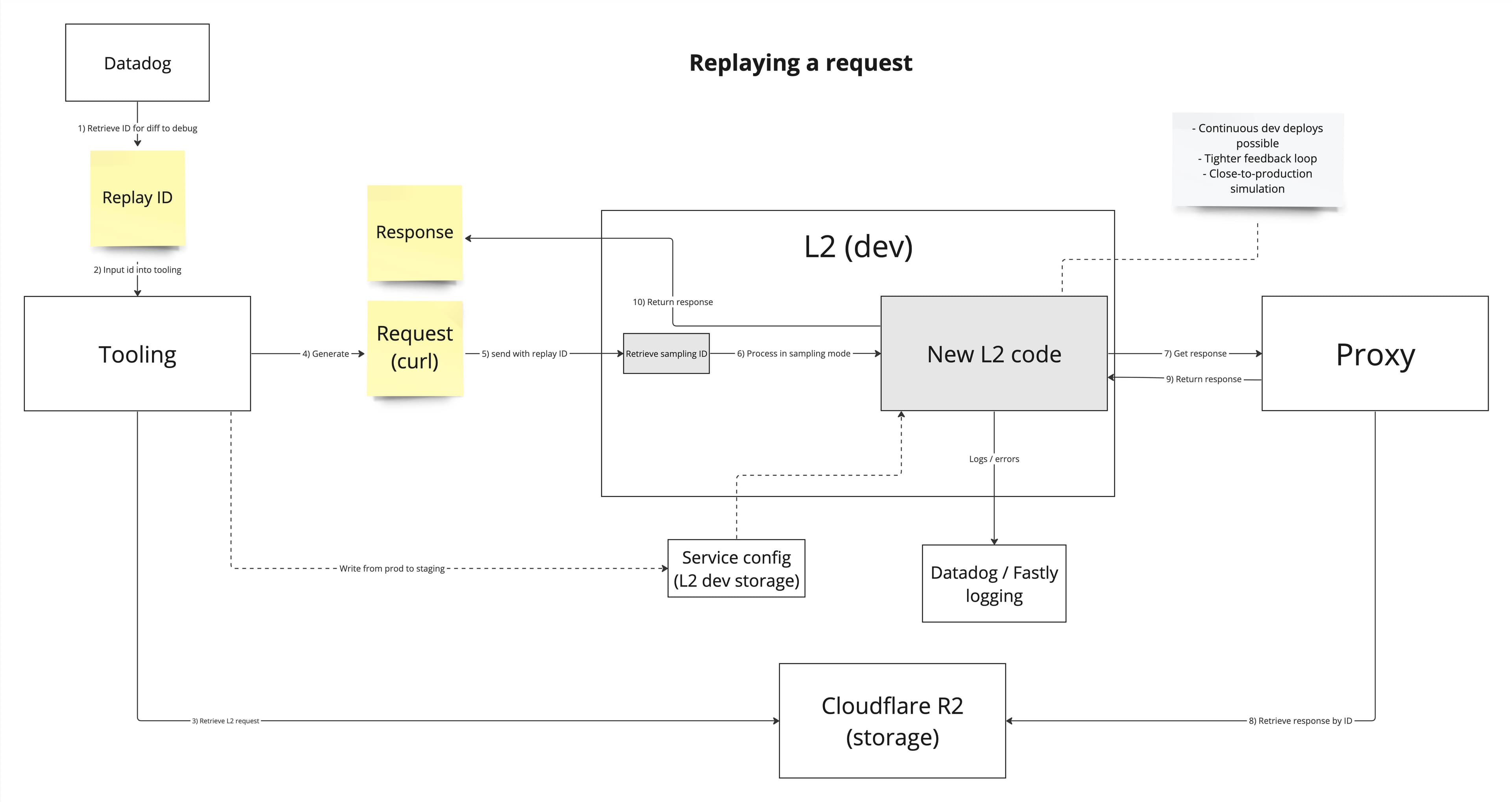
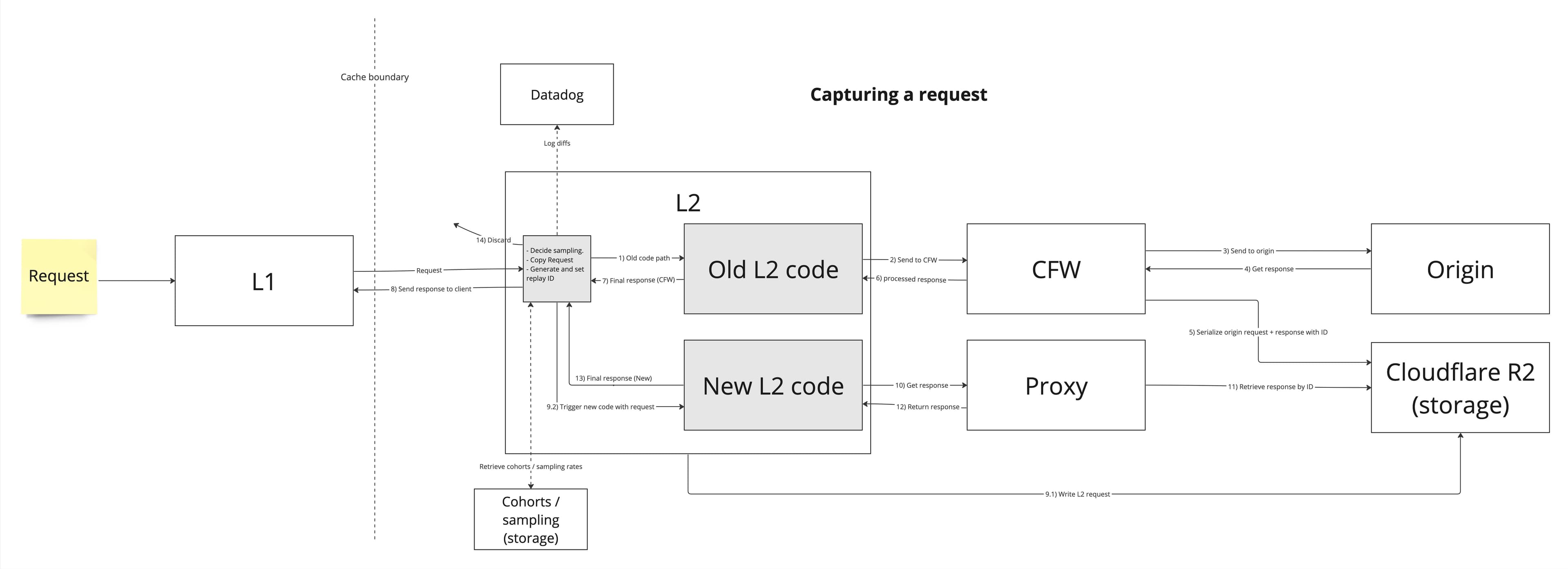
Observations
It was invaluable to us to have this system and we absolutely loved looking at the data. The usual process was easy:
Increase the sampling rate to 1-5% for a group of users.
Once 200-300 differences have been captured, turn sampling off.
🕵️ mode activated.
The good
Surrogate key mismatches
This was easily our biggest catch! "Surrogate keys" are used by our edge provider to "tag" a response and whenever we want to get rid of an item from the cache, we can purge a key and all cache entries that have this key in their list of surrogate keys, gets evicted.
One of those keys contains the variables that are used with a given field.
So for something like
query AccountCallsTableQuery($first: Int!, $after: Int, $input: SearchInput!) {todos(first: $first, after: $after, input: $input) { id }}
we would track which actual values for $first $after and $input are coming with it, distinguishing two completely different calls with the same query document.
Things like SearchInput can get really big, so we hash its value. The hashing algorithm was obviously the same in between both, but the JSON serialization had subtle differences. Notably, the null values in nested JSON objects were treated differently. This caused inconsistent hashing and could have caused great confusion if it had ever reached production.
Excessive __typenames
To make sure we can apply cache rules on a per-type basis, Stellate injects the __typename selection to any selection set that does not have it already. Based on that we do our business logic, and then remove it again where you didn't request it specifically.
As easy as that! Right..?
Turns out there we conditions in which our old system component was misbehaving and thus we found differences. Turns out the new system component had similar issues, now just in other edge-cases. Examples of excessive typenames making it to client responses:
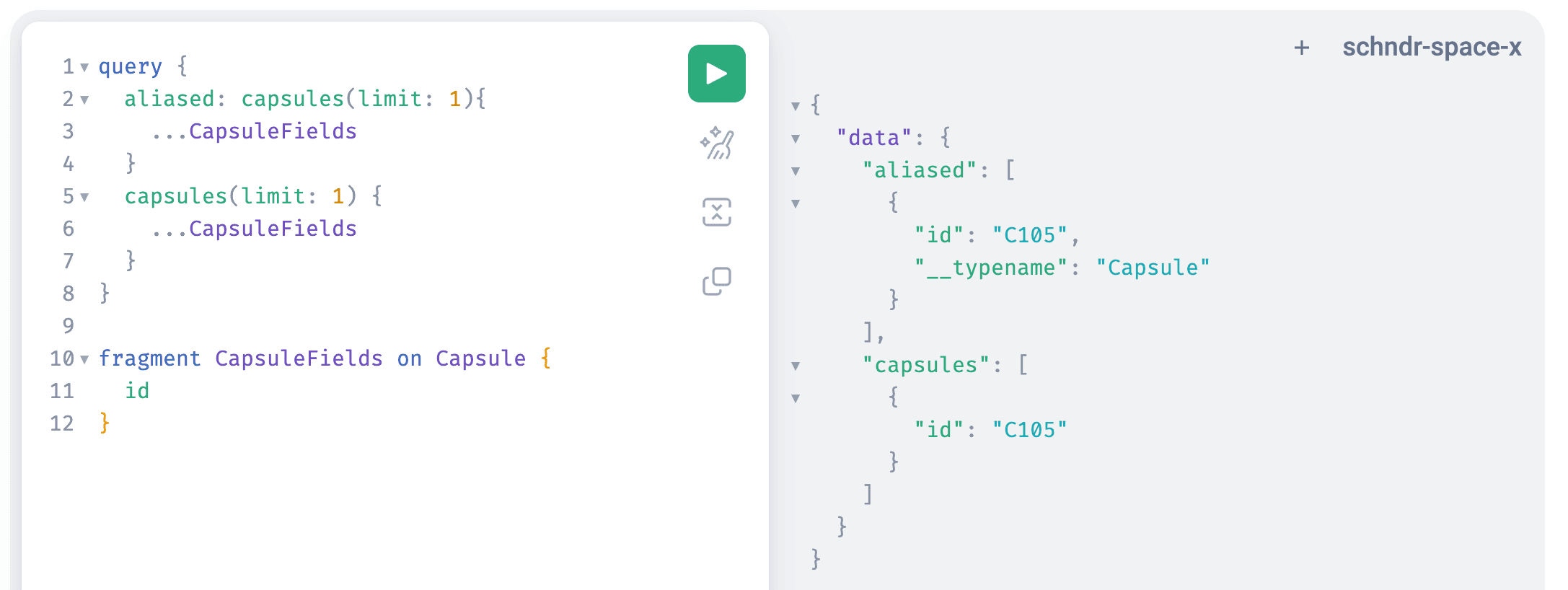
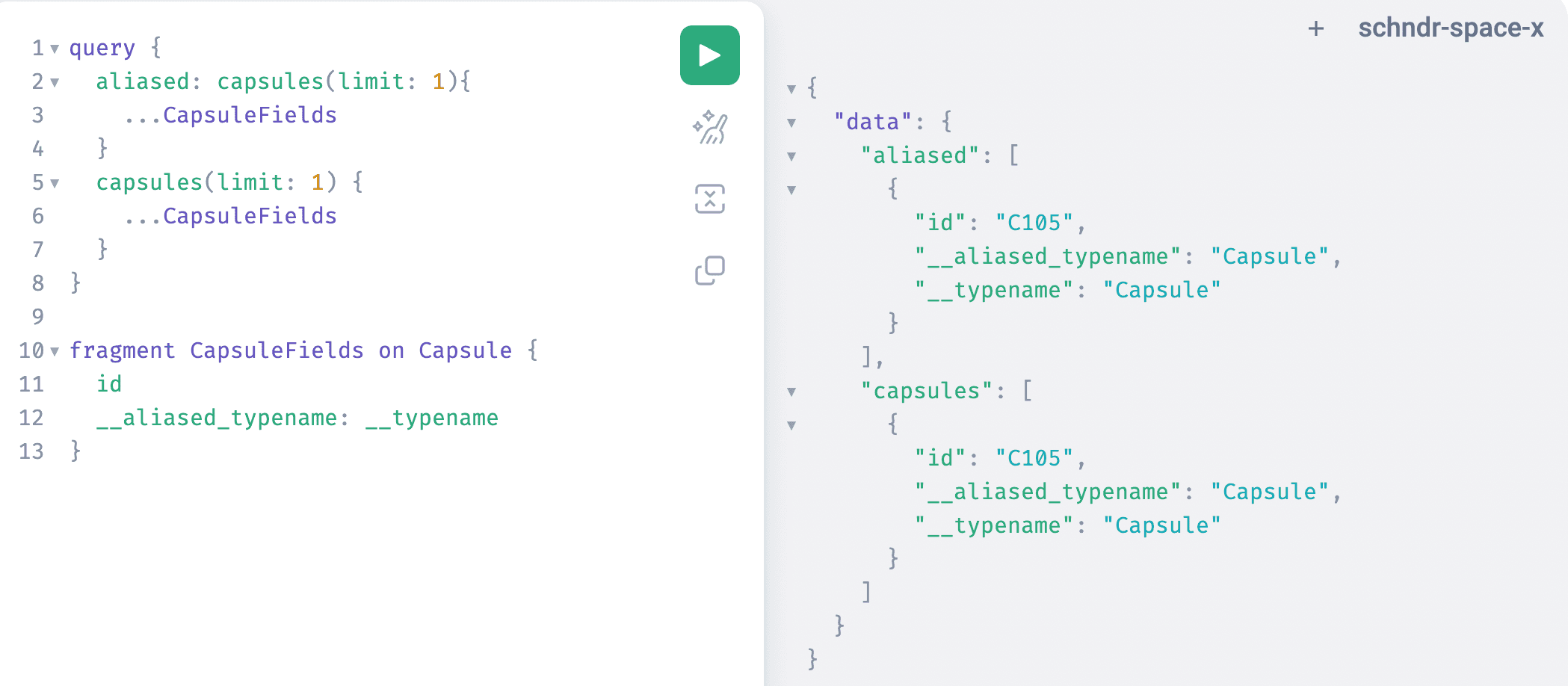
Ultimately this led us to rethink the functionality and use an alias for all selections injected by us.
query SampleRequest {authors(limit: 10) {__stellate__internal__typename: __typename # Added by Stellate (using the new alias)posts(limit: 10) {__typename # Not touched since this was already included in the original query... on BlogPost {title}... on Tweet {message}}}}
The bad
When we first rolled out the traffic replay system, we saw differences like this:

Seeing different request IDs shattered the proverbial glass on the ground: no captured response were sent back, both system components reached out to the user's origin server.
We had caused an incident bummer! We immediately turned off the sampling. Luckily we realized it quickly and had only a subset of services in the sampling process. We took accountability and reached out to all users who have had mutations in that timeframe with the exact mutations, so they could check for the impact. All other services in the sampling group also got a notification, but the harm was limited to a few duplicate read requests to their origin.
The fun
The HTTP specification

Can you spot the difference? Yep, it's the color of the comma and the whitespace within the array, you're right. I. kid. you. not!
Okay, fair, it's just how the diff was rendered, but we were so confused at first. Then it dawned at us:
The old system component collected all values for a header and joined them together into one single response header:
vary: x-preview-token, Accept-Encoding
The new system component, in an HTTP spec compliant way, did set a new HTTP header every time a response header value was set:
vary: x-preview-tokenvary: Accept-Encoding
We eventually decided to ignore this in the diff, as both ways are correct and we expect HTTP calls to be handled in a spec compliant fashion.
Numbers are odd
(pun intended?)
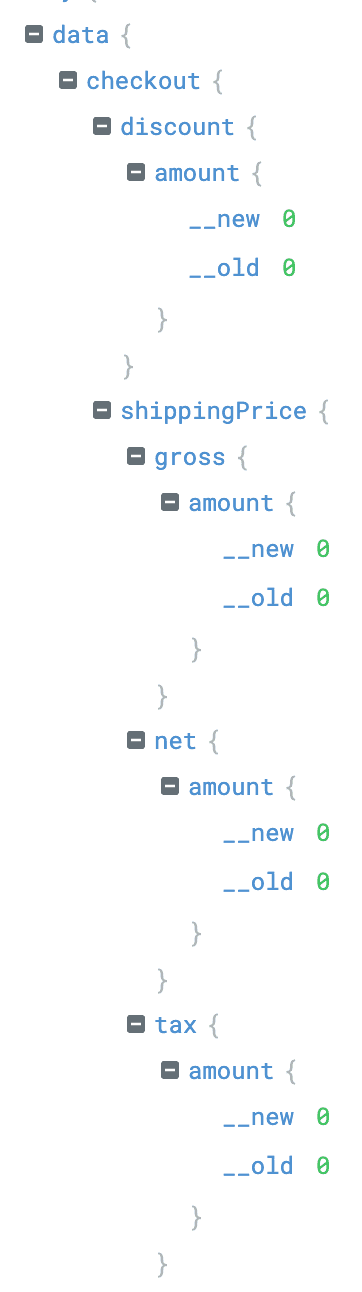
Again: Can you spot the difference between __old and __new? There is none? Again, you're right!
Personally, this was the most hilarious diff to look at and the answer is everybody's darling in computer science: number types.
uint, int, float, double.. or how JavaScript, and therefore JSON, call it: a number.
The old system component used the JavaScript based graphql-js implementation and "on the way out" also parsed the response to remove the injected __typenames (see above).
By parsing the response and serializing it again, the number treatment of JS became the output, no matter what your origin sent:
origin | internal type | output |
|---|---|---|
0 | number | 0 |
0.0 | number | 0 |
The new system component does know about more specific types than just "number", and started retaining it:
origin | internal type | output |
|---|---|---|
0 | int64 | 0 |
0.0 | float64 | 0.0 |
We started debating if this was a breaking change?
To understand, we need to look at the JSON specification, our transport layer. For numbers, JSON only requires the integer portion of a number. Additionally, if the decimal point is set, at least one more digit has to follow. No constraints are made about trailing zeros. Both values are correct.
It could hypothetically cause issues if your consuming system (e.g. an app) would not expect a floating point number to occur at this position in the response. But this would mean two things:
You ignore your GraphQL schema. GraphQL knows about floats and your field at this position is not an
Int.Your origin server is sending wrong data for the field.
Yet, we decided to be extra careful here. We went the extra mile and made sure the trailing .0 portions of all number are removed while serializing to JSON. It was a contract we established and we strive to be rather safe than sorry.
Conclusion
We hope this article gave you a better understanding of all the work and thoughts that went into migrating to our new system and ultimately provide you with 2x faster cache misses. We took a lot of care to verify the new system before migrating customers over. While it wasn’t possible to eliminate functional changes entirely, we tried to keep the changes to a minimum to make the migration as smooth as possible.
Our customers trust us with billions of business critical requests per months and we feel an incredible responsibility to live up to that trust. That is why we at Stellate put in a tremendous amount of effort in verifying changes like these before migrating production traffic and potentially impacting customer traffic.
This has only been a subset of all issues we discovered, if you're curious for more, you can always reach out to us, we're happy to chat!